




Меня зовут Олег Халилов, я сооснователь ИТ-компании Neti. Последние годы меня увлекает тема искусственного интеллекта и машинного обучения. Я люблю делать проекты, где роботы берут на себя утомительный ручной труд человека и повышают эффективность всей компании. Расскажу о кейсе, полезном для собственников бизнеса и руководителей ИТ-подразделений.
Это история о том, как с помощью нейросети мы оптимизировали ручной труд и кратно увеличили скорость обработки заявок. Если в вашей компании много входящих обращений пользователей, а менеджеры поддержки перегружены, возможно, этот опыт вам пригодится.
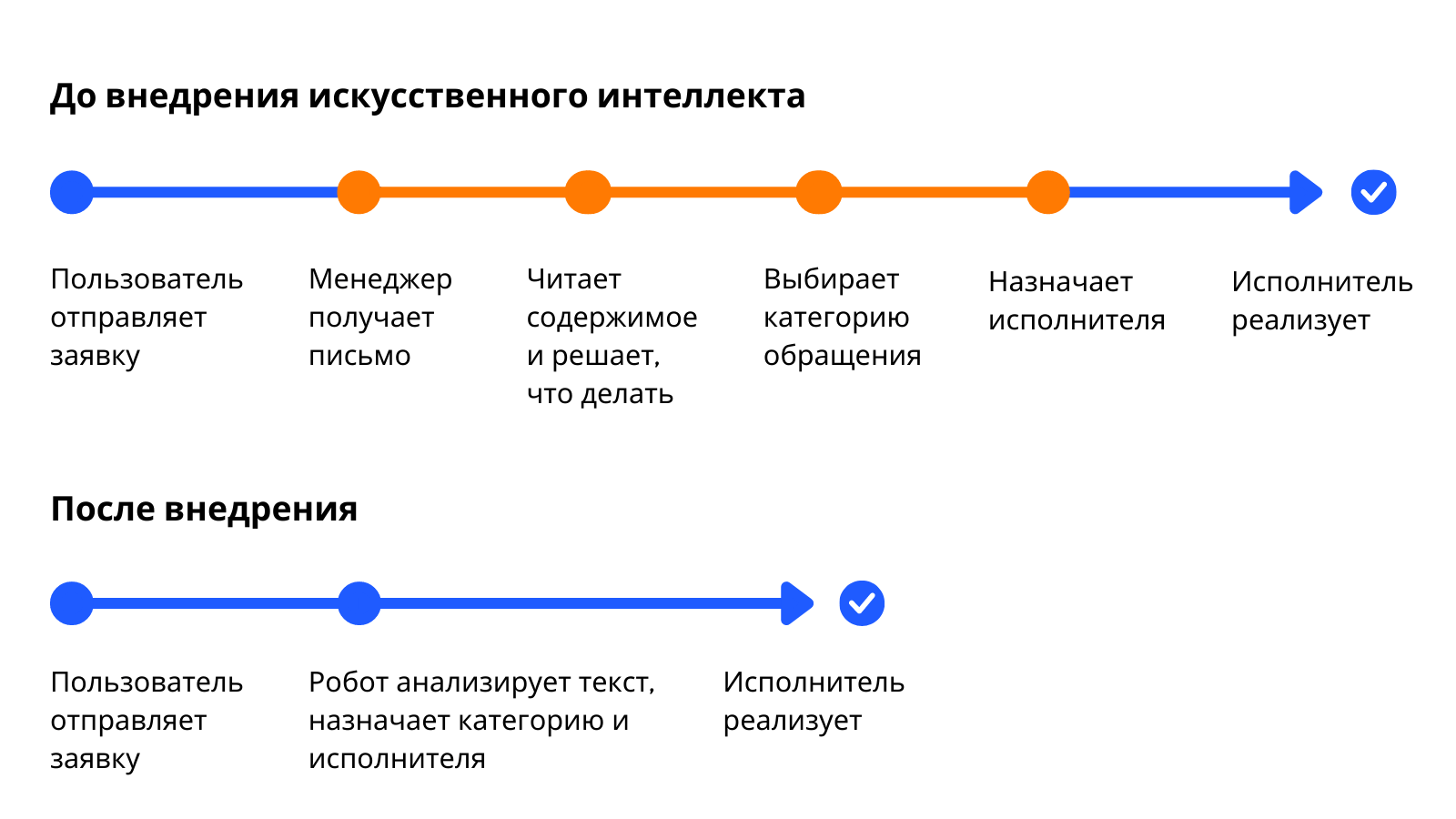
Ситуация
У нас в компании работает принцип одного окна. Сотрудники направляют запросы в бухгалтерию и отдел кадров на единый почтовый ящик: заказывают справки, присылают счета подрядчиков, запрашивают больничные. Каждую неделю набирается несколько сотен таких обращений.
Входящие заявки обрабатывает офис-менеджер. Он присваивает заявке категорию и направляет исполнителю, исполнитель выполняет и закрывает задачу. Так происходит с простыми запросами, например, выдать сотруднику справку 2-НДФЛ.
Если задача более долгая, процесс усложняется. Например, чтобы обработать заявление на отпуск, нужно несколько человек. В этом случае менеджер направляет задачу на отдел кадров и дальше ее ведет специалист отдела: согласовывает с руководителем, знакомит сотрудника с приказом на отпуск, отправляет бухгалтерам для расчета отпускных.
Задача
Такая классификация и перенаправление заявок занимает много времени и отвлекает участников процесса. При этом каждый день на менеджера сыпятся новые задачи и, если не успевать их распределять, они будут накапливаться и срывать сроки. Подрядчики с опозданием будут получать деньги, а отдел кадров не сможет вовремя принимать людей на работу.
Мы решили автоматизировать классификацию заявок. Возможностей искусственного интеллекта, чтобы читать тексты и относить их в правильную категорию, более чем достаточно. Для этого нужно выбрать нейросеть, обучить ее и интегрировать с системой управления задачами.
Решение
Подготовка системы управления проектами. Мы учитываем рабочее время и ведем задачи в Jira, она развернута на корпоративном сервере. После того как пользователь отправил запрос на специальный ящик, Jira автоматически забирает его содержимое и превращает в задачу для менеджера. Раньше менеджеру приходилось каждое обращение переносить вручную — это занимало несколько часов в день. Функционал автоматического создания задачи из письма мы реализовали до подключения нейросети.
Забегая вперед, скажу два слова про Jira и другие системы. Если бы мы работали не с Jira, а, например, с Битрикс24, то ничего принципиально бы не поменялось. Мы бы просто сделали другую интеграцию. Нейросеть можно подружить с любыми системами предприятия (ERP, CRM, 1С), системами REST API (ITSM 365, Naumen Service Desk, Итилиум, OTRS) и Service Desk системами (IntraService, Bpm’online от Terrasoft). Использование нейросетей ограничено только фантазией и наличием данных для обучения. Но к возможностям их применения я еще вернусь в конце.
Выбор нейросети. Похожие проекты по классификации заявок мы уже выполняли, только раньше использовали модель обработки текста TF-IDF с фреймворком LightGBM. В этот раз решили взять более совершенную языковую модель BERT.
BERT — это нейронная сеть, которую выпустил Google несколько лет назад. Создатели обучили сеть на 2,8 миллиардах слов и ста языках. Благодаря этому BERT понимает словоформы и синонимы, учитывает последовательность и контекст слов в предложениях.
Для наших целей этого особенно хорошо. Сотрудники могут по-разному формулировать свои запросы, а в русском языке есть слова, значения которых нейросеть сможет определить только внутри фразы или целого предложения. Например, слово «брак».

По обещаниям разработчиков, BERT должен понимать контекст и отличать разные браки.
Обучение нейросети. Основной фактор успешного проекта в ML — чистые исторические данные. Машине все равно: она обучится на любых данных и будет показывать соответствующий результат. Но если в исторических данных содержатся ошибки, смысла в этом обучении мало.
Чтобы дообучить BERT на наших данных, мы выгрузили из Jira 16 000 обращений, которые классифицировал менеджер. Затем произвели чистку: нашли и исправили ошибки, когда менеджер неправильно распределил запросы, и вручную поменяли категории.
Выявление ошибок в Big Data заняло неделю. Обучение нейросети BERT — 7 минут 26 секунд. Для ML-проектов такая разница во времени между подготовкой данных и обучением — обычное дело.
Интеграция с Jira. Для сервера, где стоит BERT, мы использовали простой компьютер семилетней давности. Обработка текстов занимает доли секунды, поэтому для автоматизации обращений хватает минимальной мощности. На сервере запустили веб-сервис на Python Flask.
Наша Jira уже умела превращать обращения сотрудников в задачи для менеджера. Чтобы подключить к этому процессу нейросеть, мы настроили в Jira автоматическую отправку запросов на сервер.
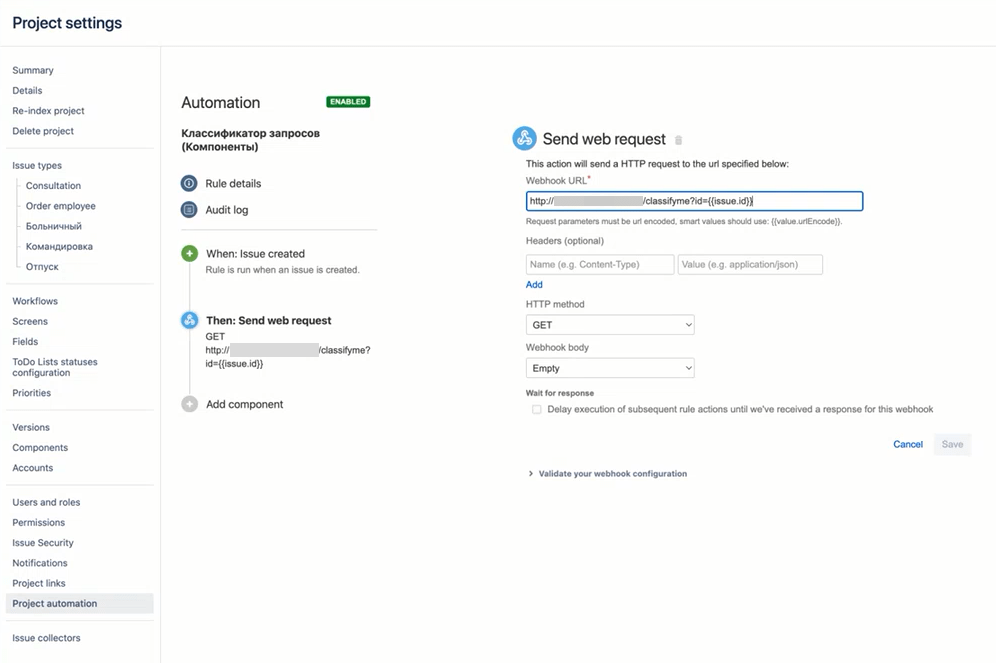
Когда приходит новое обращение, Jira отправляет запрос на веб-сервис, который сразу классифицирует текст
Теперь обработка заявок изнутри выглядит так: пользователи пишут письма на специальный email → заявка падает в Jira как задача для менеджера → Jira отправляет запрос на сервер → нейросеть читает текст заявки, назначает компоненту и, если нужно, меняет исполнителя → исполнитель выполняет и закрывает задачу.
Пользователи всего этого не видят. Для маркетолога, который отправляет счет на оплату рекламы, заявка сразу падает в бухгалтерию. Но если развернуть историю изменений в Jira, будет видна такая картина:
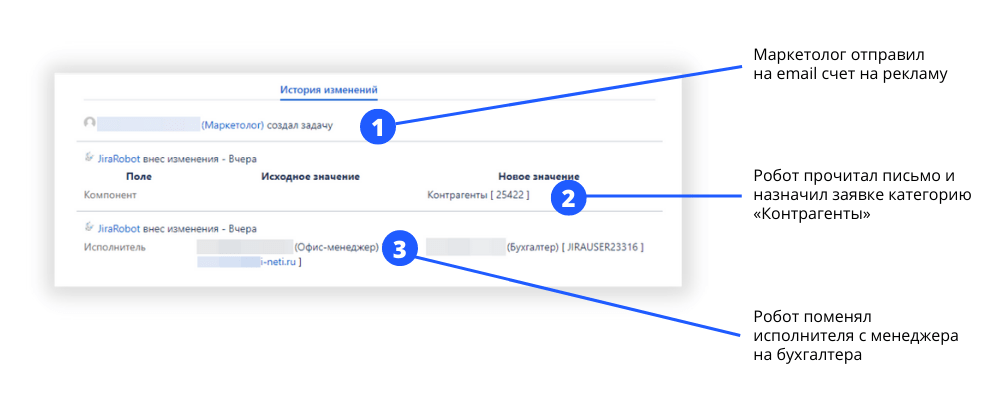
Классификация заявок роботом занимает меньше секунды и происходит незаметно для пользователей
Результат
Ускорение обработки заявок. Раньше заявления на отпуск обрабатывались по две недели: от момента, когда сотрудник прислал заявление, до выплаты отпускных. Процесс выглядел так:
Сотрудник отправлял письмо на email → менеджер видел новую задачу в Jira → переводил обращение на отдел кадров → специалист отдела кадров переводил задачу на руководителя → руководитель согласовывал и возвращал обратно → отдел кадров направлял сотруднику приказ для ознакомления → сотрудник читал и соглашался → отдел кадров переводил задачу на бухгалтерию → бухгалтеры рассчитывали отпускные и возвращали задачу назад → специалист отдела кадров закрывал заявку.
С внедрением нейросети процесс согласований упростился и теперь все происходит в разы быстрее и удобнее. Если сотрудник сразу ознакомился с приказом, то от создания до закрытия заявки проходит всего 10 минут. Задачи больше не висят по две недели. Фактически время обработки заявлений сократилось с 2 недель до 10 минут.
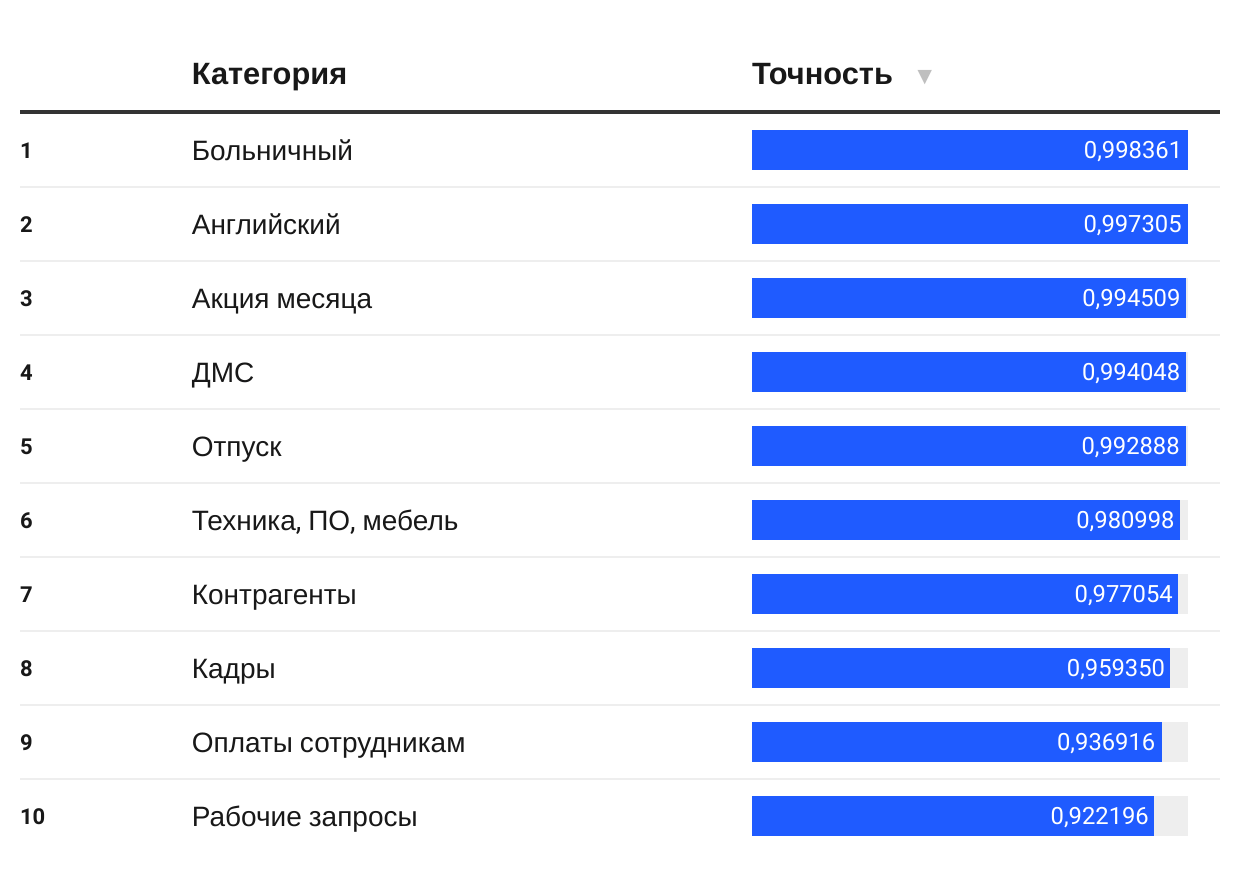
Точность распределения. Иногда нейросеть ошибается. Пользователи пишут по-разному, и робот не всегда правильно классифицирует заявку. Но справедливости ради, когда я перепроверяю ошибки, то сам не всегда понимаю, какую категорию выбрать.
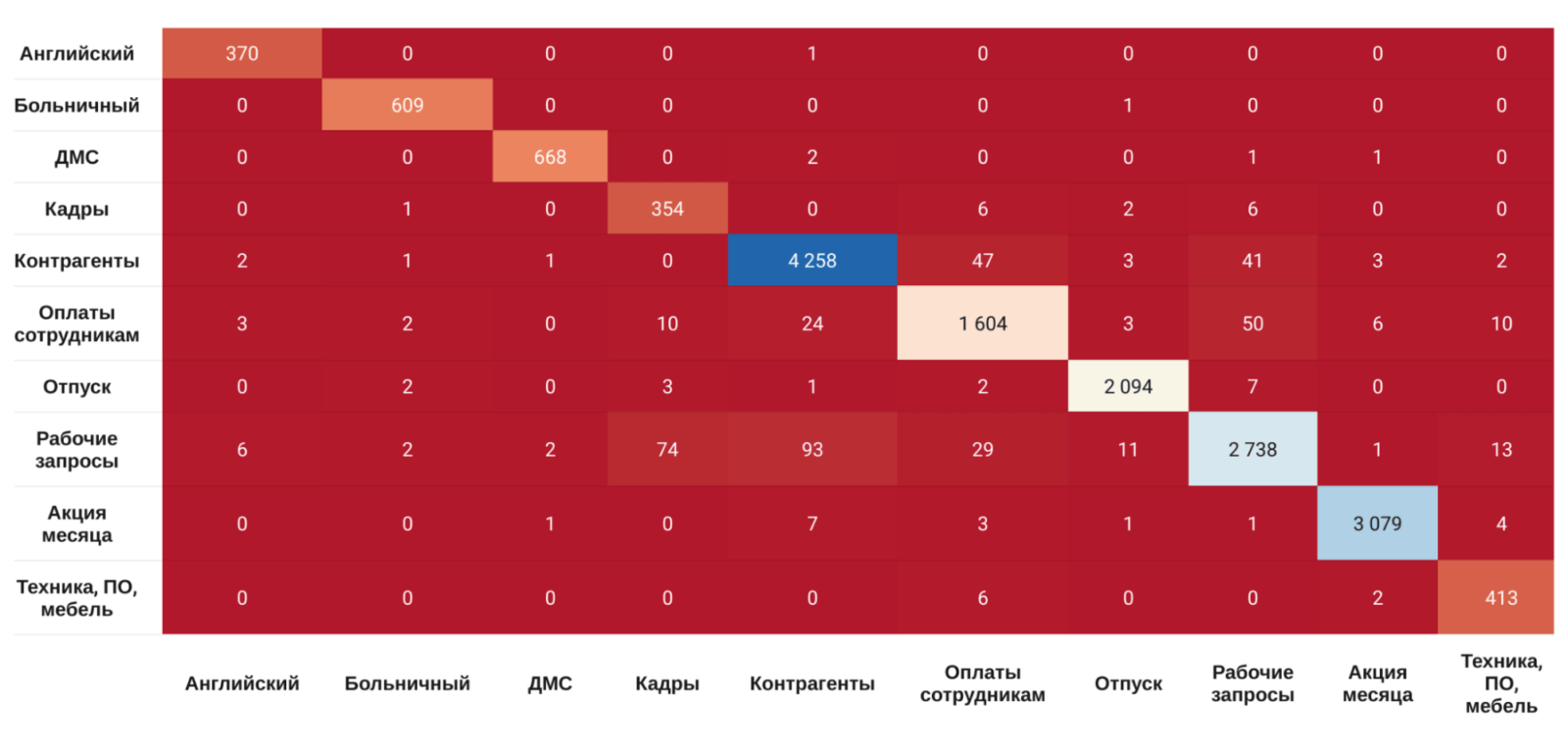
Количество правильно и ошибочно классифицированных заявок. Первая колонка по вертикали — правильная категория заявки, нижняя строчка — категория, куда заявку отнес робот
Чаще других BERT путается с категорией «Рабочие запросы». Но поскольку в эту категорию можно отнести любые обращения пользователей, это нормально.
На наших данных точность обработки заявок составляет от 92 до 99%. Раз в полгода мы проверяем найденные ошибки, вручную меняем классификаторы и заново переобучаем сеть.
Главное, что дает нейросеть — это мгновенная классификация заявок пользователей с высокой точностью. Внедрение BERT ускорило выполнение наших задач и освободило менеджеров от избыточной нагрузки.
Такую автоматизацию заявок можно применить везде, где обрабатывают и маршрутизируют запросы пользователей — от служб HelpDesk до сайта Госуслуг. BERT одинаково хорошо справляется с небольшими текстами и длинными письмами.
Если пользователи регулярно обращаются с однотипными вопросами — а таких обычно большинство — можно расширить функционал и сделать интеллектуальный автоответчик. Нейросеть будет самостоятельно отвечать на частые вопросы. В свое время мы реализовывали такой проект для Леруа Мерлен.
Если у вас есть вопросы или нужен совет по искусственному интеллекту и машинному обучению, пишите на почту.




